La migration vers des débits 400G/800G : Partie I
La planification permettant de répondre aux futurs défis des data centers commence aujourd’hui. La feuille de route de l’Ethernet expliquée.
Dans les data centers, les choses continuent à évoluer à grande vitesse.
L’accélération de l’adoption de l’infrastructure et des services cloud entraîne la nécessité d’une bande passante plus importante, de vitesses plus rapides et de performances de latence plus faibles. L’avancement de la technologie des commutateurs et des serveurs entraîne des changements dans le câblage et les architectures. Quel que soit le marché ou l’objectif de votre installation, vous devez tenir compte des changements dans votre architecture d’entreprise ou cloud qui seront probablement nécessaires pour répondre aux nouvelles exigences. Cela signifie comprendre les tendances qui favorisent l’adoption de l’infrastructure et des services cloud, ainsi que les technologies d’infrastructure émergentes qui permettront à votre organisation de répondre aux nouvelles exigences. Voici quelques éléments à prendre en compte lorsque vous planifiez l’avenir.
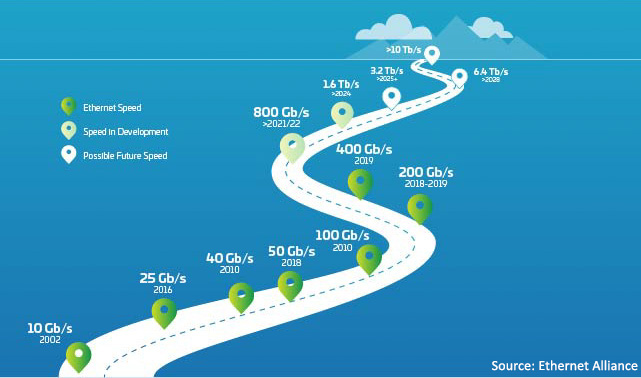
Figure 1 : Feuille de route Ethernet
Voulez-vous lire hors ligne ?
Téléchargez une version PDF de cet article pour le relire ultérieurement.
Restez informé !
Abonnez-vous à The Enterprise Source et obtenez des mises à jour lorsque de nouveaux articles sont publiés.
Utilisation globale des données
Bien entendu, au cœur des changements se trouvent les tendances mondiales qui remodèlent les attentes des consommateurs et la demande pour des communications plus rapides et plus nombreuses, telles que :
- Croissance explosive du trafic sur les réseaux sociaux
- Déploiement des services 5G, rendu possible par une densification massive des petites cellules
- Accélérer les déploiements de l’IdO et de l’IIoT (IdO industriel)
- Passage du travail traditionnel au bureau ¨à diverses options à distance
Croissance des fournisseurs hyperscale
Au niveau mondial, les véritables data centers hyperscale sont moins d’une douzaine, mais leur impact sur l’aménagement du paysage global des data centers est significatif. Selon une étude récente, le monde a passé en cumulé 1,25 milliard d’années en ligne en seulement 2020. 1Environ 53 % de ce trafic passe par une installation hyperscale.2
Partenariat Hyperscale avec les installations de data center en colocation (MTDC/co-emplacement)
À mesure que la demande pour des performances de latence plus faibles augmente, les fournisseurs hyperscale et cloud travaillent pour étendre leur présence plus près de l’utilisateur final/appareil final. Beaucoup s’associent à MTDC ou à des data centers de colocalisation pour localiser leurs services à l’extrémité du réseau3. Lorsque la périphérie est physiquement proche, une latence et des coûts de réseau plus faibles augmentent la valeur des nouveaux services à faible latence. C’est pourquoi, la croissance dans l’arène de l’hyperscale oblige les MTDC et les sites de colocation à adapter leurs infrastructures et architectures pour prendre en charge l’augmentation de l’échelle et les demandes de trafic qui sont plus typiques des data centers hyperscale. Dans le même temps, ces plus grands data centers doivent continuer à être flexibles aux demandes des clients pour des interconnexions croisées avec les rampes du fournisseur cloud.
Réseaux Mesh à architecture Leaf-Spine et tissu
La nécessité de prendre en charge des applications à faible latence, haute disponibilité et bande passante très élevée est difficilement limitée aux data centers hyperscale et de colocalisation. Toutes les installations de data center doivent maintenant repenser leur capacité à gérer les demandes croissantes des utilisateurs finaux et des parties prenantes. En réponse, les gestionnaires de data centers évoluent rapidement vers des réseaux maillés plus denses en fibres. La connectivité complète, les câbles backbone à plus haut nombre de fibres et les nouvelles options de connectivité permettent aux opérateurs réseau de prendre en charge des vitesses de voie toujours plus élevées alors qu’ils se préparent à effectuer la transition vers le 400 Gigabit par seconde4(G).
Optimiser l’apprentissage machine (ML) et l’intelligence artificielle (IA)
En outre, les plus grands fournisseurs de data centers, en partie motivés par l’IdO et les applications de ville intelligente, se tournent vers l’IA et le ML pour aider à créer et à affiner les modèles de données qui alimentent les capacités de calcul presque en temps réel en périphérie. En plus d’avoir le potentiel de permettre un Nouveau Monde d’applications (pensez à des voitures autonomes commercialement viables), ces technologies nécessitent des ensembles de données massifs, souvent appelés lacs de données, et une puissance de calcul massive dans les data centers et des tuyaux suffisamment larges pour pousser les modèles raffinés à la périphérie lorsque cela est nécessaire.5
Synchronisation du déplacement vers des débits 400G/800G
Ce n’est pas parce que vous êtes aujourd’hui à 40G ou même à 100G que vous pouvez vous reposer sur un faux sentiment de sécurité. Si l’historique de l’évolution des data centers nous a appris quelque chose, c’est que le rythme du changement, qu’il s’agisse de bande passante, de densité de fibre ou de vitesses de ligne s’accélère de manière exponentielle. La transition vers le 400G est plus proche que vous ne le pensez. Vous en doutez ? Ajoutez le nombre de ports 10G (ou plus rapides) que vous prenez en charge actuellement et imaginez qu’ils évoluent vers le 100G, vous réaliserez que le besoin de 400G (et au-delà) n’est pas si loin.
Si les gestionnaires de data centers regardent vers l’horizon, les signes d’une évolution basée sur le cloud sont partout.
Plus
de serveurs virtualisés haute performance
Une bande passante plus élevée
et une latence plus faible
Rapidité accrue
au niveau des connexions switch-to-server
Une bande passante plus élevée
vitesses de liaison montante et d’ossature
Des capacités rapides
d’expansion
Dans le cloud lui-même, le matériel est en train de changer. Plusieurs réseaux disparates typiques dans un data center existant ont évolué vers un environnement plus virtualisé qui utilise des ressources matérielles regroupées et une gestion logicielle. Cette virtualisation rend nécessaire l’acheminement de l’accès et de l’activité des applications de la manière la plus rapide possible, obligeant de nombreux gestionnaires de réseau à demander, « Comment concevoir mon infrastructure pour prendre en charge ces applications axées sur le cloud »)
La réponse commence par l’activation de vitesses plus élevées par ligne. La progression de 25 à 50 puis à 100G et au-delà est essentielle pour atteindre 400G et au-delà, et elle a commencé à remplacer la voie de migration traditionnelle 1/10G. Mais il y en a plus que l’augmentation des vitesses sur les lignes, bien plus encore. Nous devons creuser cette question un peu plus profondément.
L’industrie atteint un point d’inflexion. L’adoption du 400G s’est accélérée très rapidement, mais il est prévu que le 800G commence à augmenter encore plus rapidement que le 400G. Comme on peut s’y attendre, il n’y a pas de réponse simple à « qui ou ce qui est à l’origine de la transition vers le 400G ». Il existe toute une variété de facteurs en jeu, dont beaucoup sont liés entre eux. Les nouvelles technologies permettent de réduire le coût par bit lorsque les taux de lignes augmentent. Les derniers projets de données dont les débits de lignes 100G seront combinés avec des ports de commutation octaux pour apporter des options 800G sur le marché à partir de 2022. Ces ports sont utilisés de plusieurs façons, cependant, comme illustré dans les données6 de comptage de lumière où 400G et 800G sont principalement répartis en 4X ou 8X 100G. C’est cette application de dérivation qui est le moteur précoce de ces nouvelles applications optiques.
Figure 2 : Expéditions de port Ethernet vers data center
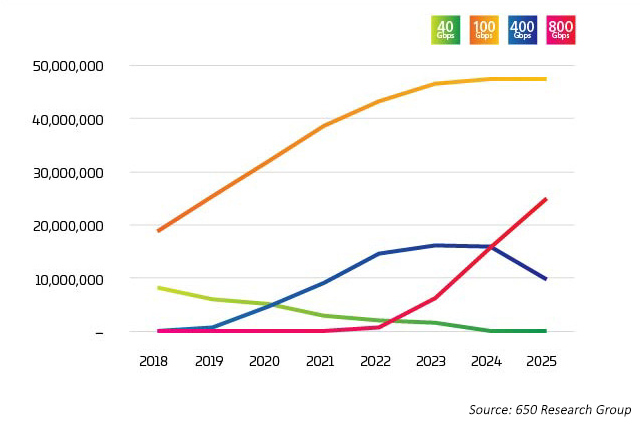
Dans un réseau de données, la capacité est une question de vérifications et d’équilibre entre les serveurs, les commutateurs et la connectivité. Chacun pousse l’autre à être plus rapide et moins coûteux, afin de suivre efficacement la demande produite par l’augmentation des ensembles de données, l’IA et le ML. Pendant des années, la technologie de commutation est restée le principal goulot d’étranglement. Avec l’introduction de StrataXGS® Tomahawk® de Broadcom3, les gestionnaires de data centers peuvent désormais augmenter les vitesses de commutation et de routage jusqu’à 12,8 Térabits/sec (Tb/s) et réduire leur coût par port de 75 %. La puce 4 de commutation Tomahawk de Broadcom, avec une bande passante de 25 Tb/s, fournit à l’industrie des data centers plus de capacité de commutation pour garder une longueur d’avance sur les charges de travail d’IA et de ML croissantes. Aujourd’hui, cette puce prend en charge 64 ports 400G ; mais à une capacité de 25,6 Tb/s, la technologie des semi-conducteurs nous fait prendre une voie où nous pourrions voir à l’avenir 32 ports 800G sur une seule puce. 32, par coïncidence, étant le nombre maximum de QSFP-DD, ou OSFP (émetteurs-récepteurs 800G) qui peut être présenté sur une face avant de commutateur 1U.
Le facteur limitant est donc la capacité de traitement du processeur. N’est-ce pas ? Faux. Plus tôt cette année, NVIDIA a lancé sa nouvelle puce Ampère pour serveurs. Il s’avère que les processeurs utilisés dans sont parfaits pour gérer la formation et le traitement basé sur l’inférence nécessaires à l’IA et au ML. Selon NVIDIA, une machine basée sur Ampère peut faire le travail de 120 serveurs Intel.
Figure 3 : Vitesses Ethernet
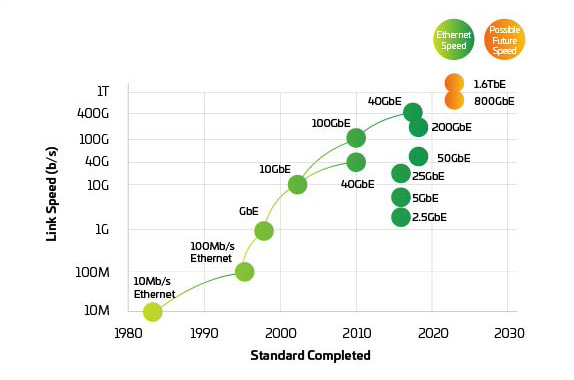
Les commutateurs et les serveurs étant programmés pour prendre en charge 400G et 800G au moment où ils sont nécessaires, la pression passe à la couche physique pour maintenir l’équilibre du réseau. IEEE 802.3bs, approuvé en 2017, a ouvert la voie à l’Ethernet 200G et 400G. Cependant, l’IEEE vient de terminer son évaluation de la bande passante concernant 800G et au-delà. L’IEEE a lancé un groupe d’étude pour identifier les objectifs des applications au-delà du 400G et, étant donné le temps nécessaire pour développer et adopter de nouvelles normes, nous sommes peut-être déjà en retard. L’industrie travaille maintenant ensemble pour introduire 800G et commence à travailler vers 1.6T et au-delà tout en améliorant la puissance et le coût par bit.
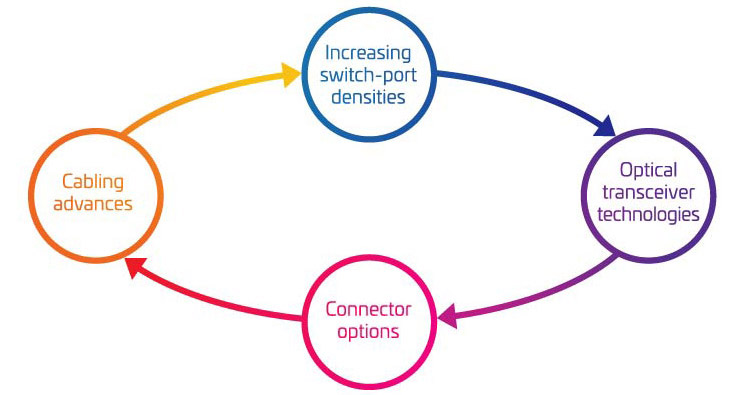
Les quatre piliers de la migration 400G/800G
Alors que vous commencez à considérer les « écrous et boulons » pour soutenir votre migration vers le 400G, il est facile d’être submergé par toutes les pièces mobiles impliquées. Pour vous aider à mieux comprendre les variables clés qui doivent être prises en compte, nous les avons regroupées dans quatre domaines principaux :
- L’augmentation des densités des commutateurs-ports
- Technologies d’émetteur-récepteur optique
- Options de connecteur
- Avances de câblage
Ensemble, ces quatre domaines représentent une grande partie de votre boîte à outils de migration. Utilisez-les pour affiner votre stratégie de migration afin de répondre à vos besoins actuels et futurs.
Les vitesses de commutation augmentent en tant que sérialiseur/désérialiseur (SERDES) qui fournit les E/S électriques pour le déplacement ASIC de commutation depuis 10G, 25G, 50G. Les SERDES devraient atteindre 100G une fois que IEEE802.3ck deviendra une norme ratifiée. Les circuits intégrés spécifiques aux applications de commutation (ASIC) augmentent également la densité des ports d’E/S (également appelée radix). Les ASIC à radix plus élevé prennent en charge plus de connexions de périphériques réseau, offrant ainsi la possibilité d’éliminer les commutateurs de couche supérieure de rack (ToR). Cela, à son tour, réduit le nombre total de commutateurs nécessaires pour un réseau cloud. (Un data center avec 100 000 serveurs peut être pris en charge avec deux niveaux de commutation avec un RADIX de 512.) Les circuits ASIC à radix plus élevé se traduisent par des dépenses d’investissement (moins de commutateurs), des dépenses d’exploitation (moins d’énergie nécessaire pour alimenter et refroidir moins de commutateurs) et des performances réseau améliorées grâce à des latences plus faibles.
Figure 4 : Effets des commutateurs Radix supérieurs sur la bande passante du commutateur
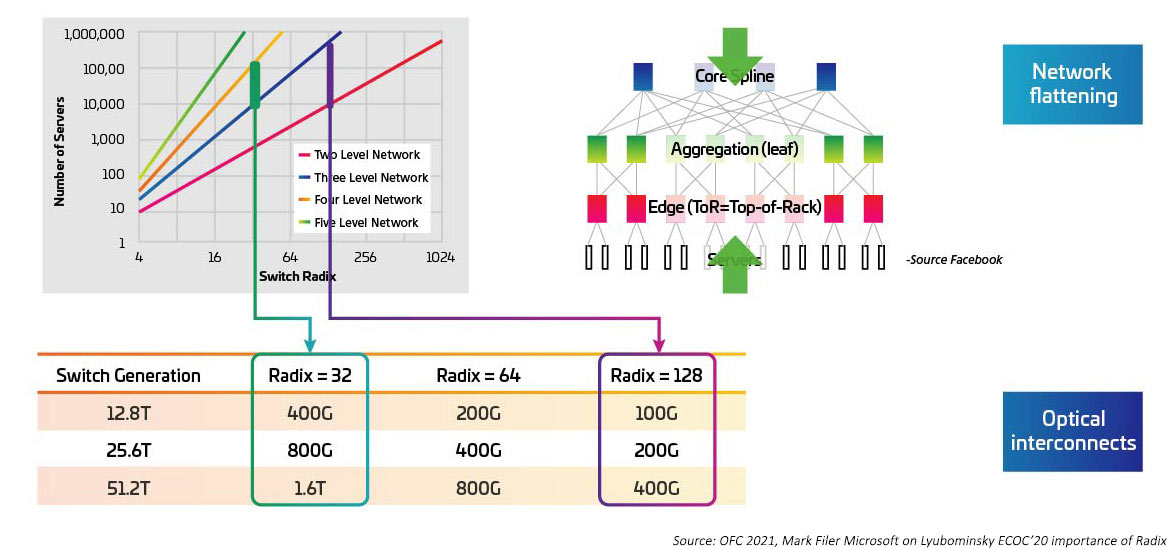
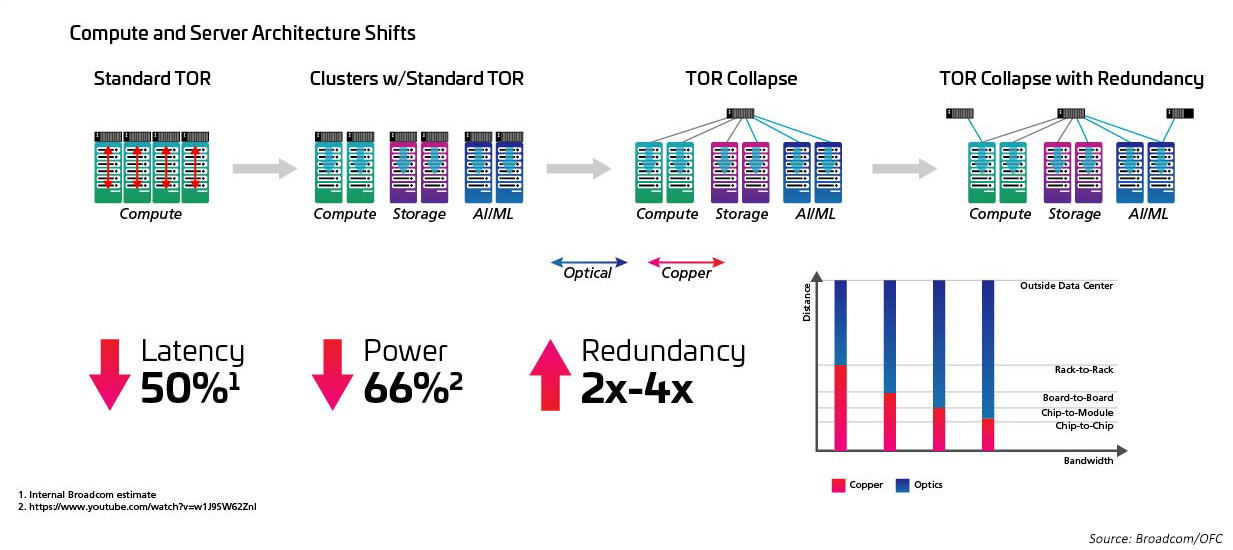
Le passage d’une topologie ToR (top-of-rack) à une configuration de mi-rang (Med-of-row) ou de fin de rangée (End-of-row) est étroitement lié à l’augmentation du radix et à la vitesse de commutation, et à l’avantage que présente une approche de câblage structuré lors de la facilitation des nombreuses connexions entre les serveurs en ligne et les commutateurs MoR/EoR. La capacité à gérer le grand nombre de pièces jointes de serveur avec une plus grande efficacité est nécessaire pour utiliser de nouveaux commutateurs à radiogène élevé. Cela, à son tour, nécessite de nouveaux modules optiques et un câblage structuré, tels que ceux définis dans la norme IEEE802.3cm. La norme IEEE802.3cm prend en charge les avantages des émetteurs-récepteurs enfichables pour une utilisation avec des applications de réseau de serveurs à haut débit dans de grands data centers définissant huit pièces jointes hôtes à un émetteur-récepteur QSFP-DD.
Figure 5 : Architectures passant de ToR à MoR/EoR
Tout comme l’adoption du facteur de forme QSFP28 a conduit à l’adoption du 100G en offrant une densité élevée et une consommation d’énergie inférieure, le passage au 400G et au 800G est rendu possible par de nouveaux facteurs de forme d’émetteur-récepteur. Les optiques SFP, SFP+ ou QSFP+ actuelles sont suffisantes pour permettre des vitesses de liaison 200G. Cependant, le passage au 400G nécessitera de doubler la densité des émetteurs-récepteurs. Pas de problème.
Le QSFP-Double Density (QSFP-DD7) et octal (2 fois un quad)et les accords multi-sources (MSA) enfichables à petit facteur de forme (OSFP8) permettent aux réseaux de doubler le nombre de connexions d’E/S électriques à l’ASIC. Il permet non seulement d’additionner plus d’E/S pour atteindre des vitesses agrégées plus élevées, mais également au nombre total de connexions d’E/S ASIC d’atteindre le réseau.
Le facteur de forme du commutateur 1U avec ports 32 QSFP-DD correspond 256 (32x8) aux E/S ASIC. De cette façon, nous pouvons créer des liaisons à haut débit entre les commutateurs (8*100 ou 800G) mais nous avons également la possibilité de maintenir le nombre maximal de connexions lors de la connexion des serveurs.
Nouveaux formats d’émetteurs
Le marché de l’optique pour la 400G est stimulé par les coûts et les performances, les OEM essayant d’accéder au point d’ancrage et à l’échelle cloud des data centers. En 2017, le CFP8 est devenu le facteur de forme du module 400G de première génération à utiliser dans les routeurs principaux et les interfaces client de transport DWDM. L’émetteur-récepteur CFP8 était le type de facteur de forme 400G spécifié par le CFP MSA. Les dimensions du module sont légèrement inférieures à celles du CFP2, tandis que les optiques prennent en charge les E/S électriques CDAUI-16 (16x25G NRZ) ou CDAUI-8 (8x50G PAM4). Quant à la densité de bande passante, elle prend respectivement en charge huit fois et quatre fois la densité de bande passante de l’émetteur-récepteur CFP et CFP2.
Les modules de facteur de forme 400G de deuxième génération sont dotés des technologies QSFP-DD et OSFP. Les émetteurs-récepteurs QSFP-DD sont rétrocompatibles avec les ports QSFP existants. Ils s’appuient sur le succès des modules optiques existants, QSFP+ (40G), QSFP28 (100G) et QSFP56 (200G).
L’OSFP, comme les optiques QSFP-DD, permet l’utilisation de huit lignes contre quatre. Les deux types de modules prennent en charge les 32 ports d’une carte 1RU (commutateur). Pour prendre en charge la rétrocompatibilité, l’OSFP nécessite un adaptateur OSFP-to-QSFP.
Figure 6 : OSFP VS émetteur-récepteur QSFP-DD

Modes de modulation
Les ingénieurs réseau utilisent depuis longtemps la modulation de non-retour à zéro (NRZ) pour 1G, 10G et 25G, en utilisant la correction d’erreur avant (FEC) côté hôte pour permettre des transmissions à plus longue distance. Pour passer de 40G à 100G, l’industrie s’est simplement tournée vers la parallélisation des modulations NRZ 10G/25G, en utilisant également le FEC côté hôte pour les longues distances. Lorsqu’il s’agit d’atteindre des vitesses de 200G/400G et plus rapidement, de nouvelles solutions sont nécessaires.
Figure 7 : Des schémas de modulation à plus grande vitesse sont utilisés pour activer les technologies 50G et 100G.
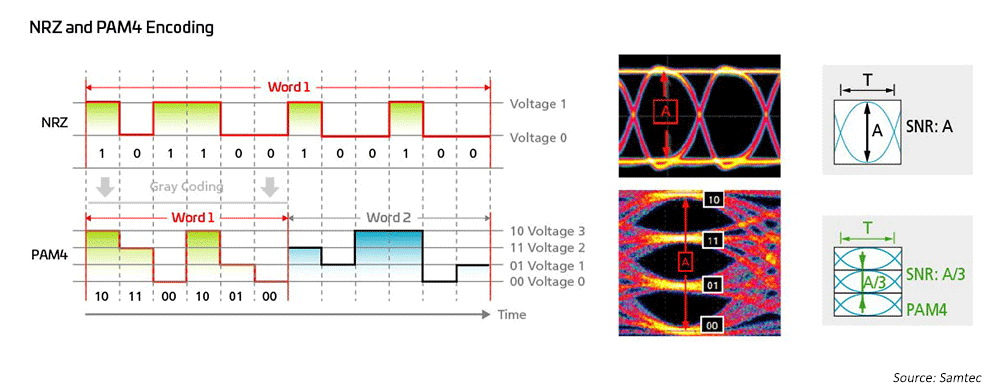
Par conséquent, les ingénieurs en réseau optique ont recours à la modulation d’amplitude d’impulsions à quatre niveaux (PAM4) pour concrétiser les architectures réseau à bande passante ultra-élevée ; PAM4 est la solution actuelle pour 400GPAM4. Ceci est basé sur une mesure importante du système IEEE802.3, qui a complété de nouvelles normes Ethernet pour des débits allant jusqu’à 400G (802.3bs/cd/cu) pour les applications multimodes (MM) et monomodes (SM). Une grande variété d’options de dérivation sont disponibles pour s’adapter à diverses topologies de réseau dans des data centers à grande échelle.
Des schémas de modulation plus complexes impliquent la nécessité d’une infrastructure qui peut fournir une meilleure perte de retour et atténuation.
Prédictions – OSFP VS QSFP-DD
En ce qui concerne l’OSFP par rapport au QSFP-DD, il est trop tôt pour dire quelle sera la direction que prendre l’industrie ; ces deux facteurs de forme sont en effet pris en charge par les principaux fournisseurs de commutateurs Ethernet de data center et tous deux bénéficient d’une assistance client étendue. L’entreprise préférera peut-être le QSFP-DD comme une amélioration de l’optique actuelle basée sur le QSFP. L’OSFP semble repousser l’horizon avec l’introduction de l’OSFP-XD, en étendant le nombre de lignes à l’avenir16, avec un regard désormais porté sur des taux de ligne 200G.
Pour des vitesses allant jusqu’à 100G, le QSFP est devenu une solution incontournable en raison de sa taille, de sa puissance et de son avantage financier par rapport aux émetteurs-récepteurs duplex. Le QSFP-DD s’appuie sur ce succès et fournit une rétrocompatibilité qui permet l’utilisation d’émetteurs-récepteurs QSFP dans un commutateur avec la nouvelle interface DD.
S’agissant de l’avenir, beaucoup pensent que l’empreinte 100G du QSFP-DD sera populaire pour les années à venir. La technologie OSFP peut être privilégiée pour les liaisons optiques DCI ou celles nécessitant spécifiquement une puissance plus élevée et plus d’E/S optiques. Les partisans de l’OSFP envisagent des émetteurs-récepteurs 1.6T et peut-être 3.2T à l’avenir.

Les optiques emballées conjointement (CPO) fournissent une voie alternative à 1.6T et 3.2T. Mais les CPO auront besoin d’un nouvel écosystème qui peut rapprocher l’optique des circuits ASIC de commutation pour atteindre les vitesses accrues tout en réduisant la consommation d’énergie. Cette piste est en cours de développement dans le Forum d’Internetworking optique (Optical Internetworking Forum, OIF). L’OIF discute maintenant des technologies qui pourraient être les mieux adaptées au « prochain taux », avec de nombreuses personnes qui soutiennent un doublement jusqu’à 200G. D’autres options comprennent plus de lignes, peut-être 32, car certains pensent que plus de lignes et des taux de lignes plus élevés seront nécessaires pour suivre le rythme de la demande réseau à un coût de réseau abordable.
La seule prévision sûre est que l’infrastructure de câblage doit disposer de la flexibilité intégrée pour prendre en charge vos futures topologies de réseau et exigences de liaison. Alors que les astronomes ont longtemps affirmé que chaque photon compte pendant que les concepteurs réseau cherchent à réduire l’énergie par bit à quelques pJ/bit9, la conservation à tous les niveaux est importante. Un câblage haute performance aidera à réduire les frais généraux du réseau.
Les commutateurs évoluent pour fournir plus de lignes à des vitesses plus élevées tout en réduisant le coût et la puissance des réseaux. Les modules octaux permettent à ces liaisons supplémentaires de se connecter via l’espace de 32 ports d’un commutateur 1U. Le maintien du radix supérieur est accompli en utilisant l’éclatement de voie du module optique.
La grande variété d’options technologiques de connecteurs offre plus de moyens de décomposer et de distribuer la capacité supplémentaire que les modules octaux fournissent. Les connecteurs comprennent des connecteurs parallèles 8-, 12-, 16- et des connecteurs à 24 fibres optiques multiples (MPO) ou à fibres optiques duplex parallèles, ainsi que des connecteurs LC, SN, MDC et CS. Voir ci-dessous pour en savoir plus.
Figure 8 : Options de distribution de capacité à partir de modules octaux
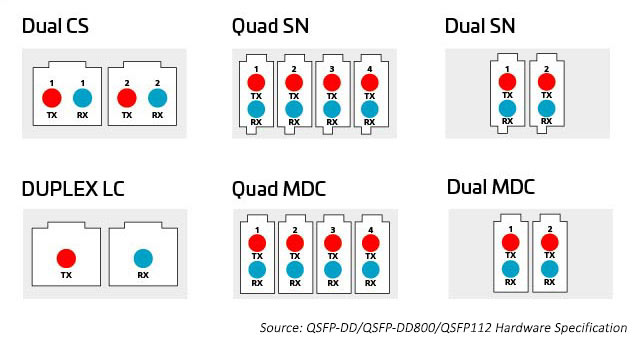
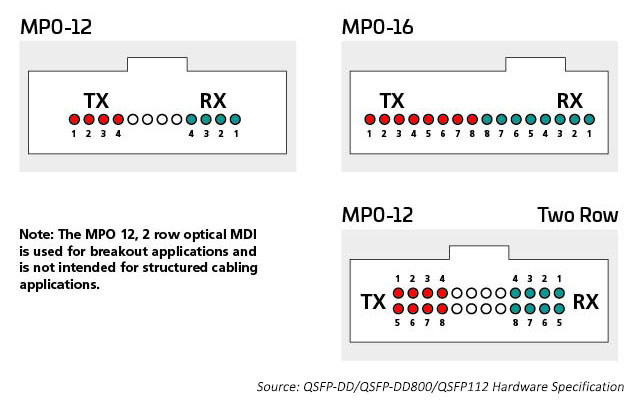
Connecteurs MPO
Jusqu’à récemment, la principale méthode de connexion des commutateurs et des serveurs au sein du data center impliquait un câblage organisé autour 12de -ou 24 fibres, généralement à l’aide de connecteurs MPO. L’introduction de la technologie octale (huit lignes de commutation par port de commutation) permet aux data centers de faire correspondre le nombre accru d’E/S ASIC (actuellement 256 par commutateur ASIC) avec les ports optiques. Cela donne le nombre maximal d’E/S disponibles pour connecter des serveurs ou d’autres périphériques.
Les E/S optiques utilisent des connecteurs appropriés pour le nombre de lignes optiques utilisées. Un émetteur-récepteur 400G peut avoir un connecteur LC duplex unique avec une E/S optique 400G, il peut également avoir 4 X E/S optiques 100G nécessitant des 8 fibres. Les connecteurs duplex MPO12 ou peut-être 4 SN s’adaptent au boîtier de l’émetteur-récepteur et fournissent les 8 fibres dont cette application a besoin. Seize fibres sont nécessaires pour faire correspondre les E/S 8 électriques et optiques, préservant le radix de l’ASIC du commutateur. Les ports optiques peuvent être monomodes ou multimodes en fonction de la distance à laquelle la liaison est conçue.
Par exemple, la technologie multimode continue de fournir les débits de données optiques à grande vitesse les plus rentables pour les liaisons à courte portée dans le data center. Les normes IEEE prennent en charge la technologie 400G dans une liaison unique (802,3 400G SR4.2), qui utilise quatre fibres pour transmettre et quatre fibres pour recevoir, chaque fibre transportant deux longueurs d’onde. Cette norme étend l’utilisation des techniques de multiplexage bidirectionnel par répartition en longueur d’onde (BiDi WDM) et était initialement destinée à prendre en charge les liaisons commutateur à commutateur. Cette norme utilise le connecteur MPO12 et a été la première à optimiser l’utilisation de l’OM5 MMF.
Le maintien du radix du commutateur est important lorsque de nombreux périphériques, tels que les racks de serveurs, doivent être connectés au réseau. Le 400G SR8, conforme à la norme IEEE 802.3cm (2020), prend en charge huit connexions de serveur utilisant huit fibres optiques pour transmettre et huit fibres optiques pour recevoir. Cette application a obtenu le soutien des opérateurs cloud. Des architectures MPO-16 sont déployées pour optimiser cette solution.
Les normes monomodes prennent en charge des applications à plus longue portée (commutateur à commutateur, par exemple). IEEE 400G-DR4 prend en charge la portée des 500 compteurs avec des 8 fibres. Cette application peut être prise en charge par MPO-12 ou MPO-16. La valeur de l’approche 16 fibres est une flexibilité supplémentaire ; les gestionnaires de data centers peuvent diviser un circuit 400G en liaisons 50/100G gérables. Par exemple, une connexion 16 fibres au niveau du commutateur peut être décomposée pour prendre en charge jusqu’à huit serveurs se connectant à 50/100G tout en correspondant à la fréquence de la voie électrique. Les connecteurs MPO 16 fibres sont codés différemment pour empêcher la connexion avec les connecteurs MPO 12 fibres.
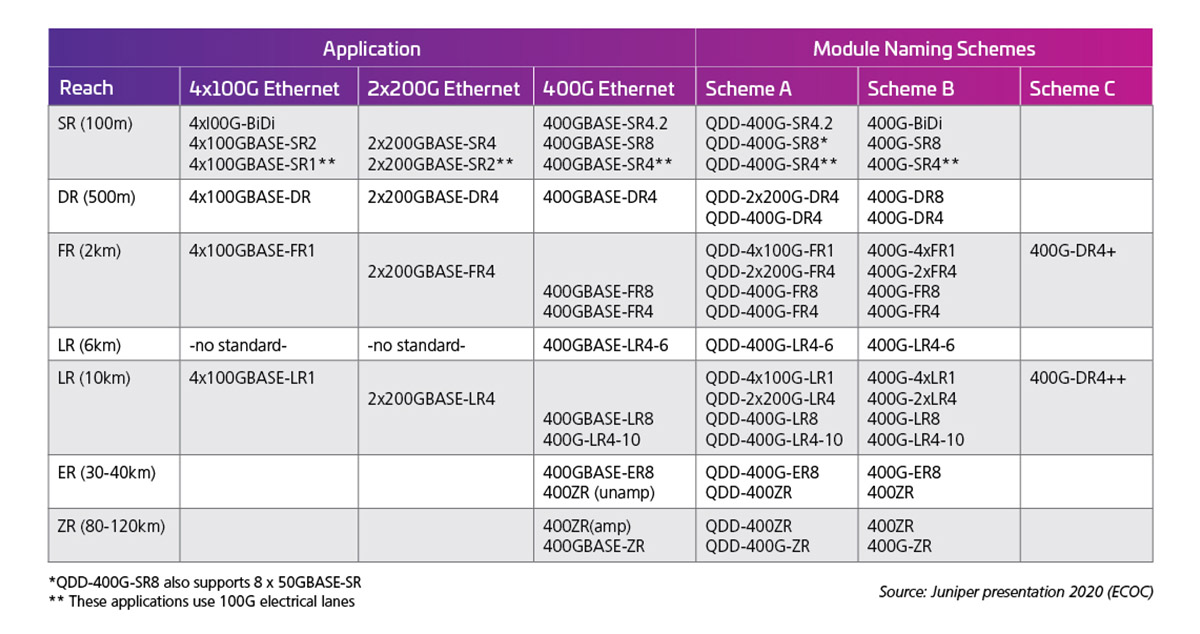
La fréquence de la voie électrique détermine ensuite les capacités de sortie de l’interface optique. Le tableau 1 montre des exemples des normes/possibilités du module 400G (50G X 8).
Tableau 1 : Capacité 400G QSFP-DD avec lignes électriques 50G
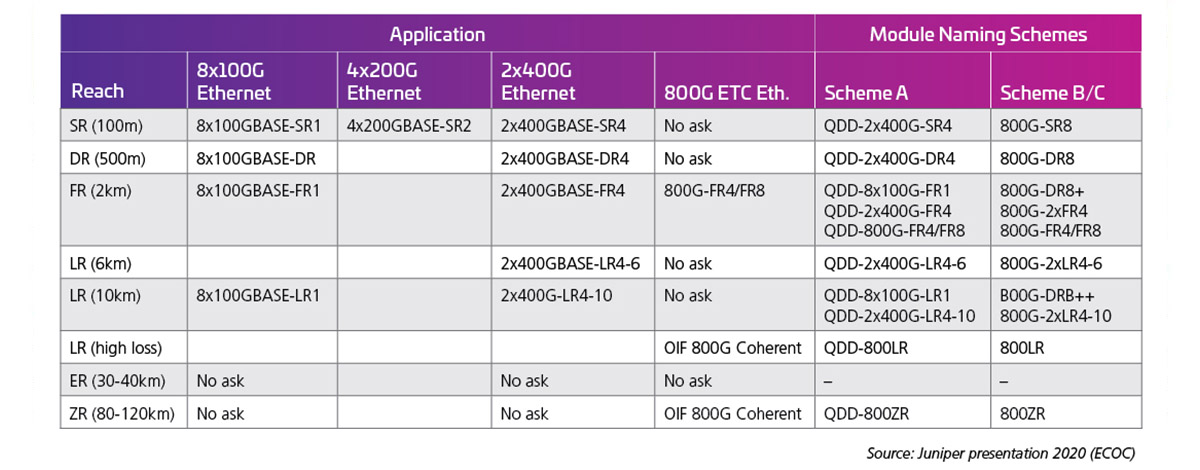
Lorsque les débits de voie sont doublés jusqu’à 100G, les interfaces optiques suivantes deviennent possibles. Au moment de la rédaction de ce document, les normes de taux de voie 100G (802,3 ck) n’ont pas été respectées ; cependant, les premiers produits sont commercialisés et un grand nombre de ces possibilités sont en fait expédiées. Le tableau 2, présenté à l’ECOC 2020 par J. Maki (Juniper), montre l’intérêt précoce de l’industrie pour les modules 800G.
Tableau 2 : Capacité 800G QSFP-DD avec lignes électriques 100G
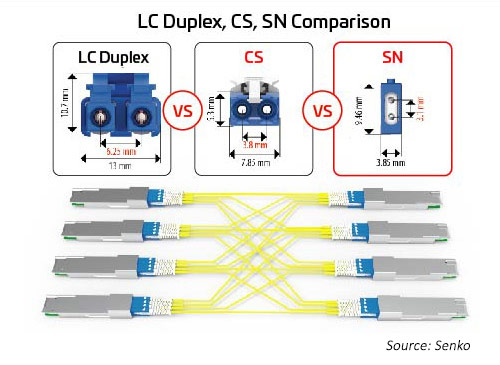
Connecteurs duplex
À mesure que le nombre de voies et les vitesses de ligne augmentent, le fractionnement des E/S optiques devient plus attrayant. Comme mentionné précédemment, les modules octal peuvent prendre en charge les options de connecteur pour 1.2 4 ou liaisons 8 duplex. Toutes ces options peuvent être prises en charge à l’aide d’un connecteur MPO ; cependant, cette option peut ne pas être aussi efficace que des connecteurs duplex séparés. Un connecteur duplex avec une empreinte réduite peut aider à activer ces options. Le SN, un connecteur de fibre optique duplex à très petit facteur de forme (VSFF), convient à cette application. Il intègre la même technologie d’embout de 1,25 mm que celle utilisée précédemment dans les connecteurs LC. Par conséquent, il offre les mêmes performances optiques et la même résistance, mais il est destiné à des options de dérivation plus flexibles pour les modules optiques à grande vitesse. Le connecteur SN peut fournir quatre connexions duplex à un module émetteur-récepteur octal. Les premières applications du SN consistent principalement à activer les applications de dérivation de module optique.
Figure 10 : Relation de taille entre les principaux connecteurs duplex et les applications de dérivation pour la migration 400G/800G
Limites de vitesse du connecteur ?
Les connecteurs n’imposent généralement pas de vitesse, contrairement à l’économie. Les technologies optiques ont été initialement développées et déployées par des prestataires de services qui disposaient des moyens financiers et des demandes en bande passante nécessaires pour soutenir leur développement, ainsi que par les liaisons longue distance les plus économiquement reliées en utilisant le plus petit nombre de fibres optiques. Aujourd’hui, la plupart des prestataires de services préfèrent la technologie de connecteur simplex ou duplex couplée à des protocoles de transport optique qui utilisent des technologies de connecteur à fibre unique comme LC ou SC.
Cependant, ces solutions longue distance peuvent être trop coûteuses, en particulier lorsqu’il y a des centaines ou des milliers de liaisons et des distances de liaison plus courtes à parcourir ; les deux conditions sont typiques d’un data center. Par conséquent, les data centers déploient souvent une optique parallèle. Étant donné que les émetteurs-récepteurs parallèles offrent un coût inférieur par Gigabit, la connectivité basée sur MPO est une bonne option sur des distances plus courtes. Ainsi, les choix de connecteurs actuels ne sont pas tant motivés par la vitesse, mais plus par le nombre de voies de données qu’ils peuvent prendre en charge, l’espace qu’ils occupent et l’impact du prix sur les émetteurs-récepteurs et les technologies de commutation.
Dans l’analyse finale, la gamme d’émetteurs-récepteurs optiques et de connecteurs optiques s’élargit, grâce à une grande variété de conceptions de réseau. Les data centers Hyperscale peuvent choisir de mettre en œuvre une conception optique très personnalisée ; étant donné l’ampleur de ces acteurs du marché, les organismes de normalisation et les OEM réagissent souvent en développant de nouvelles normes et opportunités de marché. Par conséquent, l’investissement et l’échelle sont à la pointe de l’industrie dans de nouvelles directions et les conceptions de câblage évoluent pour prendre en charge ces nouvelles exigences.
Découvrez les dernières avancées en matière de câblage, lisez La migration vers le 400G/800G : partie II.

Propel™ : la plateforme de fibre optique haute débit

Solutions de centre de données d’entreprise

Solution
Data centers Cloud et Hyperscale

Solution
Data centers en colocation

Solution
Fournisseurs de services pour centres de données

Connaissances approfondies
Fibre optique multimode : le dossier d’information
Ressources
Bibliothèque de migration haut débit

Infos sur les spécifications
OSFP MSA

Infos sur les spécifications
QSFP-DD MSA
Spécification
Matériel QSFP-DD


À première vue, le domaine des partenaires d’infrastructure potentiels qui s’attaquent à votre entreprise semble assez encombré. Il n’y a pas de pénurie de fournisseurs prêts à vous vendre des fibres optiques et de la connectivité. Mais lorsque vous vous rapprochez et réfléchissez à ce qui est essentiel pour la réussite à long terme de votre réseau, les choix commencent à se réduire. C’est parce qu’il faut plus que de la fibre et de la connectivité pour alimenter l’évolution de votre réseau... beaucoup plus. C’est là que CommScope se démarque.
Une performance éprouvée : L’histoire de l’innovation et des performances de CommScope s’étend sur 40plusieurs années, notre fibre monomode TeraSPEED® a été lancée trois ans avant la première norme OS2, et notre multimode large bande pionnier a donné naissance au multimode OM5. Aujourd’hui, nos solutions de fibre optique et cuivre end-to-end et l’intelligence AIM prennent en charge vos applications les plus exigeantes avec la bande passante, les options de configuration et les performances à perte ultra faible dont vous avez besoin pour croître en toute confiance.
Agilité et adaptabilité : Notre portefeuille modulaire vous permet de répondre rapidement et facilement aux demandes changeantes de votre réseau. Ensembles de câbles monomodes et multimodes préconnectorisés, panneaux de brassage hautement flexibles, composants modulaires, connectivité MPO 8à 24 fibres 12et 16-, connecteurs duplex et parallèles à très faible facteur de forme. CommScope vous maintient rapide, agile et opportuniste.
Tourné vers l’avenir : Lorsque vous migrez du 100G au 400G, du 800G et au-delà, notre plateforme de migration haut débit offre un chemin clair et gracieux vers des densités de fibres optiques plus élevées, des vitesses de voie plus rapides et de nouvelles topologies. Réduisez les niveaux de réseau sans remplacer l’infrastructure de câblage, passez à des réseaux de serveurs à plus haut débit et à plus faible latence à mesure que vos besoins évoluent. Une plateforme robuste et agile vous emmène d’aujourd’hui à la prochaine.
Fiabilité garantie : Grâce à notre Assurance d’application, CommScope garantit que les liaisons que vous concevez aujourd’hui répondront à vos exigences d’application des années plus tard. Nous soutenons cet engagement avec un programme holistique de service du cycle de vie (planification, conception, mise en œuvre et exploitation), une équipe mondiale d’ingénieurs d’application sur le terrain et la garantie de 25 ans de CommScope.
Disponibilité mondiale et soutien local : L’empreinte mondiale de CommScope comprend la fabrication, la distribution et les services techniques locaux qui s’étendent sur six continents et comprennent des professionnels 20 000 passionnés. Nous sommes là pour vous, quand et où vous avez besoin de nous. Notre réseau mondial de partenaires garantit que vous disposez des concepteurs, installateurs et intégrateurs certifiés pour faire avancer votre réseau.





1 Digital Trends 2020 ; thenextweb.com
2 The Golden Age of HyperScale; Data Centre magazine; 30 novembre 2020
3 https://attom.tech/wp-content/uploads/2019/07/TIA_Position_Paper_Edge_Data_Centers.pdf
4 https://www.broadcom.com/blog/switch-phy-and-electro-optics-solutions-accelerate-100g-200g-400g-800g-deployments
5 The Datacenter as a Computer Designing Warehouse-Scale Machines Third Edition Luiz André Barroso, Urs Hölzle, and Parthasarathy Ranganathan Google LLC. Morgan & Claypool publishers pg 27
6 LightCounting presentation for ARPA-E conference - octobre 2019.pdf (energy.gov)
7 http://www.qsfp-dd.com/wp-content/uploads/2021/05/QSFP-DD-Hardware-Rev6.0.pdf
8 https://osfpmsa.org/assets/pdf/OSFP_Module_Specification_Rev3_0.pdf
9 Andy Bechtolsheim, Arista, OFC 21
La transition vers des débits 400Gb risque d'arriver plus vite que vous ne le pensez
Obtenez la sélection des signes qui indiquent l’évolution du DC basé dans le Cloud.